




We all want to get things done quickly and get instant results. Don't worry, everyone does think the same way and it is nothing bad. We can use this mindset to our advantage by working smartly and planning on how to get more things done in less time. Fine, that's a topic for another day.
Similarly, we hate spending time on repetitive tasks which are time-consuming. But what if I told you we humans need not perform such tasks and it all can be handled by computers?
Think of this scenario: you have a list of over 1000 random numbers and want to find whether a particular number is present in the list. It takes a lot of your time to go through all the numbers in the list and see if it is present or not. Here is when the Searching algorithm gets handy and does this task in seconds.
The Searching Algorithm
Searching algorithms are used to check if an element is present in any data structure (list, array, tuples ).
This algorithm can be modified according to our needs like
returning the index of the number
returning true or false
returning the element itself
and many more.
The search algorithm is mainly of 2 types:
Linear search
Binary search
Let's dive deep into it.
LINEAR SEARCH
It is also called sequential search and is the simplest search. It can be performed on both sorted and unsorted arrays. We run the loop from the 0th index to the index where the target is present, and if the target is found, we break the loop, otherwise, we search the entire array for the target element.
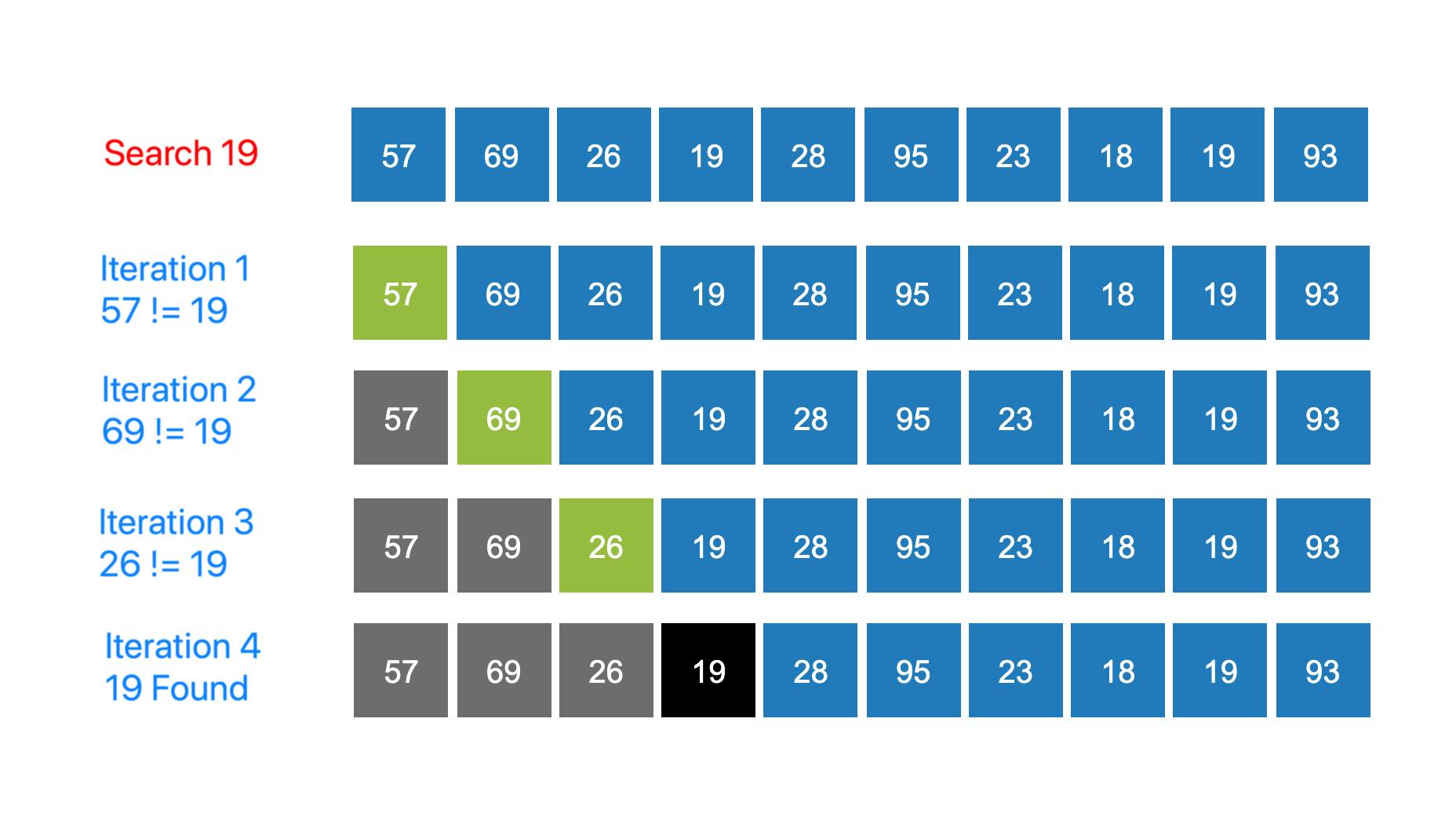
Steps
Check the target element
Create a loop to run through the array from the 0th index to the last index
Compare the element in the array with the target with each iteration.
If the target equals the element, return that particular index and the loop terminates.
If the loop runs until the end, the target is not found, so we return -1 to indicate the element is not present. We can also print "The element is not found".
let's look into an example
public static void main(String[] args){
// the array given to us is
int[] array = {2, 4, 5, 1, 10, 3};
// the target element is
int target = 5;
// We can use either use for-loop or while-loop to run through the array
for(int i = 0; i < array.length; i++){
// here it returns the index of the target if it is present
if(array[i] == target){
return i;
}
}
return -1; // if element is not present it return -1;
}
Time and space complexity
Best case: When the target element is in the 0th index of the given array we only run the loop once. In this case, the time complexity is O(1)
Worst case: When the target element is not present in the array, the loop runs till the end of the array. Therefore the time complexity is O(n). Here, n is the length of the array.
Space complexity: O(1)
Advantages of using linear search
The array need not be sorted to perform this search.
The search is faster if the target is closer to the beginning of the array.
Disadvantages
- The search is very slow as each element in the array needs to be checked.
BINARY SEARCH
Binary search is used to find the target element as well but in a sorted array, either ascending or descending. So, if you find that the array given in the question is sorted, you can blindly proceed with a binary search. This search is useful if many elements are in the array because we don't want to iterate repeatedly.
Here, the concept is we shrink the array from both ends until we find the target element exponentially.
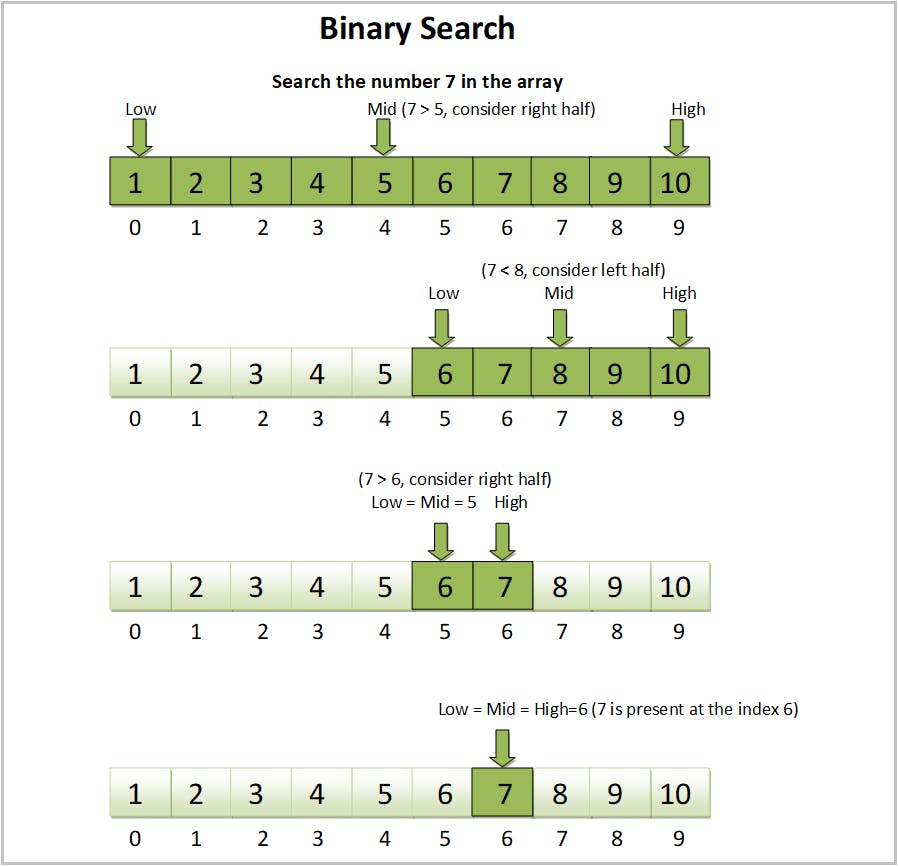
Steps
Check the target number and create a variable to store it.
Also, create a start variable and assign it to 0 indicating the number at the 0th index, and an end variable to the last index of the array that is (length of array-1).
So, always start = 0, and end = (array.length - 1).
Now, we have to find the element in the middle index. How do we do it?
Simple, It is (start + end)/2.
A more optimised way of doing it is start + (end - start)/2. if you simplify this expression you will get the same output. Think about it and try it yourself.
We do this step inside a loop (while) because the middle element will change according to the start and end values in each iteration. Here the base condition for the outer while loop will be while(start <= end). Because logically, we cannot shrink the array if there is no array to shrink.
int[] array = {1,2,3,4,5,6,7,8};
int target = 4;
int start = 0;
int end = array.length - 1; // 9 - 1 -> 7
while(start <= end){
int mid = (start + end)/2; // (0 + 7)/2 -> 3
}
Now we have to check if the element in the middle is greater, lesser, or equal to the target element.
If the target equals the middle element then life becomes easy, we simply return the element(or its index) at the middle.
int[] array = {1,2,3,4,5,6,7,8}; int target = 4; int start = 0; int end = array.length - 1; // 9 - 1 -> 7 int mid = (start + end)/2; // (0 + 7)/2 -> 3 while(start <= end){ if(array[mid] == target){ return mid; // here the middle element is the target } }If the target > middle element then we assign the start value to mid + 1.
As we know that the array is sorted the elements before the mid will also be less than the target element. Then why should we check it and waste time?
int[] array = {1,2,3,4,5,6,7,8}; int target = 7; int start = 0; int end = array.length - 1; // 9 - 1 -> 7 int mid = (start + end)/2; // (0 + 7)/2 -> 3 while(start <= end){ if(array[mid] == target){ return mid; // here the middle element is the target } else if(target > array[mid]){ start = mid + 1; } }If the target < middle element then we assign the end value to mid - 1.
Why not mid? If the target is the middle element it would have returned it in the first check itself i.e., we already have a check to see if the target is equal to mid or not. If you haven't understood it read from the second point again carefully.
int[] array = {1,2,3,4,5,6,7,8};
int target = 7;
int start = 0;
int end = array.length - 1; // 9 - 1 -> 7
int mid = (start + end)/2; // (0 + 7)/2 -> 3
while(start <= end){
if(array[mid] == target){
return mid; // here the middle element is the target
}
else if(target > array[mid]){
start = mid + 1;
}
else{
end = mid - 1; // When target < array[mid]
}
}
Advantages of using binary search
It is quicker than the linear search.
With each iteration, it reduces the search space by half.
Example
Suppose there are 1024 elements in an array.
when we use linear search
To traverse the whole array we need to iterate 1024 times (remember O(N)).
But for binary search
To traverse the whole array we need to iterate only 10 times.
The search space difference is humongous right?
Why 10 times? You will understand when we look at the time complexity for binary search.
Disadvantages
This algorithm works only when the array is sorted.
When used with recursion, it takes up a lot of space in the stack memory
Time complexity
The time complexity for binary search is O(logN). Let's take the above example, an array of 1024 elements, to understand this.
Let's substitute the number of elements in the place of N in O(logN).
$$log_2(1024)$$
We get
$$2^{10}$$
So we can conclude that it takes 10 iterations to traverse the whole array.
Best case - O(1) When the target element is the middle element.
Worst case - O(logN) When the element is the largest or the smallest in the array.
Here, space complexity is O(1).
That's the end folks. Try practicing it with pen and paper until you understand the algorithm. Try creating an array with different conditions and perform these algorithms. That's how we understand algorithms.
Thanks for reading till the end. If you enjoyed reading this blog and found it valuable, please like it and follow me on Hashnode for similar content. See you there!